Computer Organization CH4 The Processor
Computer Organization CH4 The Processor
4.1 intro
intro p3
performance
- ISA is diff. -> instruction count diff.
- clock cycle and CPI diff.
- determined by processor
CH4
- a more realistic pipeline versio
instruction execution overview p4
- started from program counter(PC)
- 讀取程式的第一條指令的位置
- in modern architecture, L1 cache
- read 1 or 2 registers
- use ALU after reading the register
- find next inst. in memory address
- arithmetic-logical inst.
- memory addr. calculation
- conditional branches
- find next inst. in memory address
- diff. by inst. classes
- read p5
前兩步驟一樣
- simplicity and regularity of RISC-V inst. set
- simplify implementation
instruction execution flow
- 資料會被複製,給多個東西看
- p6
cont’d
- 少了multiplexors
- control unit
- p7
4.2 logic design conventions
Logic design basics p10
state or not state
- output depend only on the current input -> not state
- output is related to state & input
edge trigger
- will do something
4.3 building datapath
datapath
除了32個register,還有其他奇奇怪怪的register
p15
R-format ALU
- p16
Load/Store
- p17
- immediate會先進去
- 之後再執行inst.
- p18
branch
- PC relative addres
- half word
- p21
compose the ele.
use multiplexers
- p24
- p25
- 多了ALU control
- condition branch used
4.4 A simple implementation scheme
ISA vs. Hardware design
RISC-V
- 指令的format比較複雜,但layout繼承下來
- rd都在rd, rs都在rs
- 簡化了hardware的path設計
- 相對MIPS
- 位置會做變化,需要多一個multiplexor做判斷
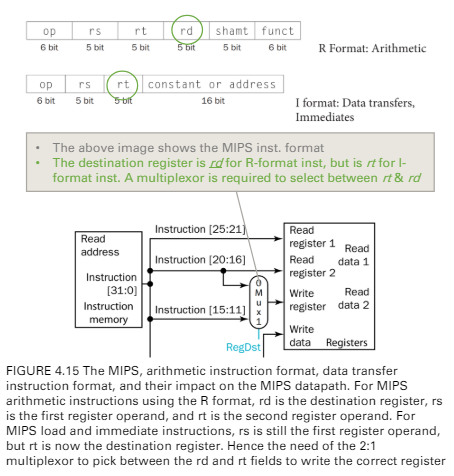
- 位置會做變化,需要多一個multiplexor做判斷
Setting of the Main Control Unit
大概就是上一節的內容
- opcode的長相
- using flow map to compare
- 圖很重要
- focus on multiplexor

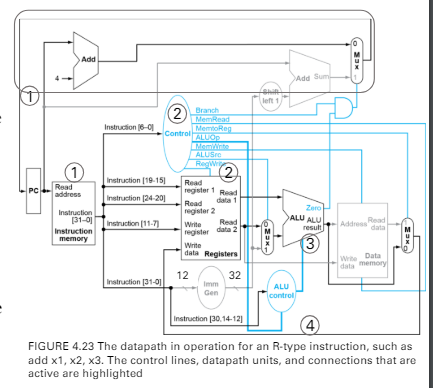
exxcution flow of R-format inst.
add x1, x2, x3- 假設指令已經被載入pc
- opcode會被送到main control
- 對所有控制訊號輸出
- ALU op
- 10 r-type
- 00 加法
- 01 減法
- 10 r-type
execution flow of I-format inst.
lw x1, offset(x2)- ALU op
- 00 lw or sw
- 00 加法
- 00 lw or sw
- 多了第四個步驟
- 造成執行時間變長
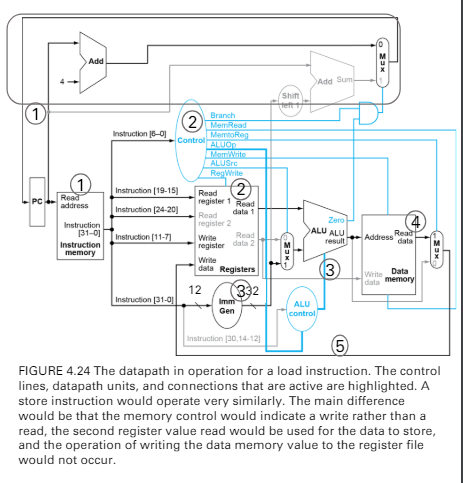
- 造成執行時間變長
execution flow of branch inst.
beq x1, x2, offset- control & result decide next PC

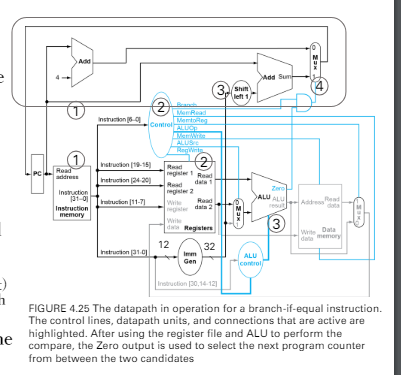
logic of the control unit
opcode 和 control unit的對比
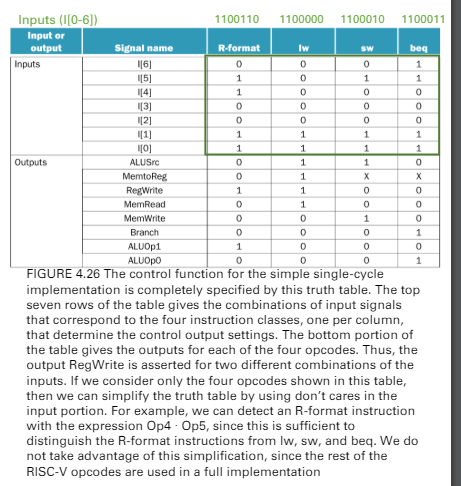
以執行時間最長的指令為一個clock period

4.6 an overview of pipeline
pipeline
sequential laundry
- 比較久
pipelined laundry - 最大效率使用各種資源
- 沒有減少每個工作的時間
- 但盡量的使用了閒置的資源
- 最快就是比seq.快4倍
single cycle vs. pipeline performance

- 以最長的major function units為pipeline的cycle
- 沒有相依性的情況

- 沒有相依性的情況
insights of the design for pipeline execution

Hazards
- structure
- 增加硬體資源可以解決
- data
- pipeline會被stalled
- control
- 存在branch
- 不知道要執行branch後的,還是PC+4

structure Hazard
- 假設只有1個memory,1個port
- 只能有一個人對memory存取
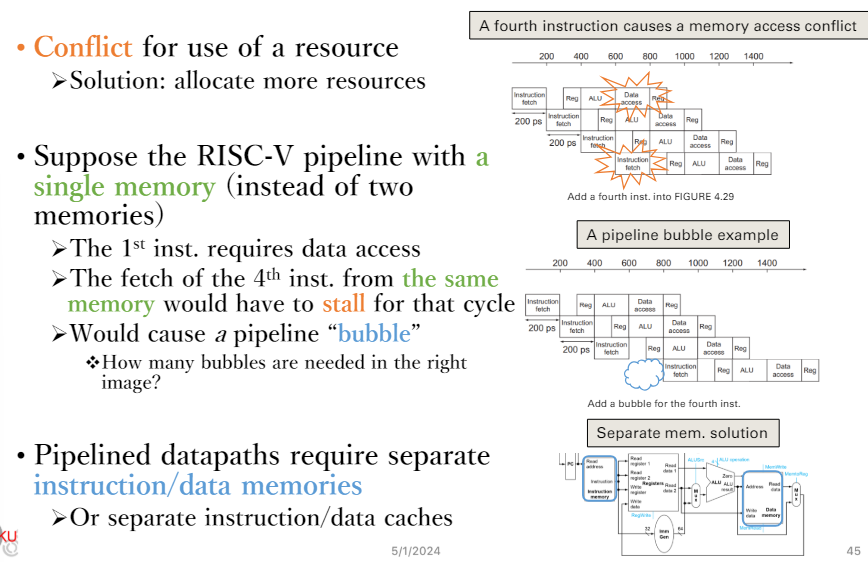
- 只能有一個人對memory存取
graphical repre. of the pipeline
- 黑色在右邊
- 讀取
- 黑色在左邊
- 寫入
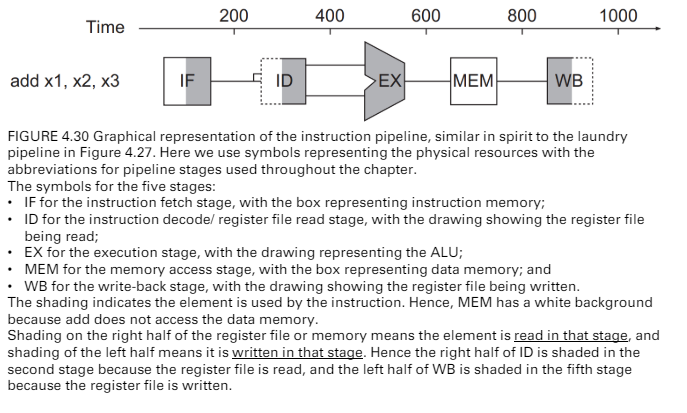
- 寫入
data hazard
- 一個指令寫入的結果,是另外一個指令的來源
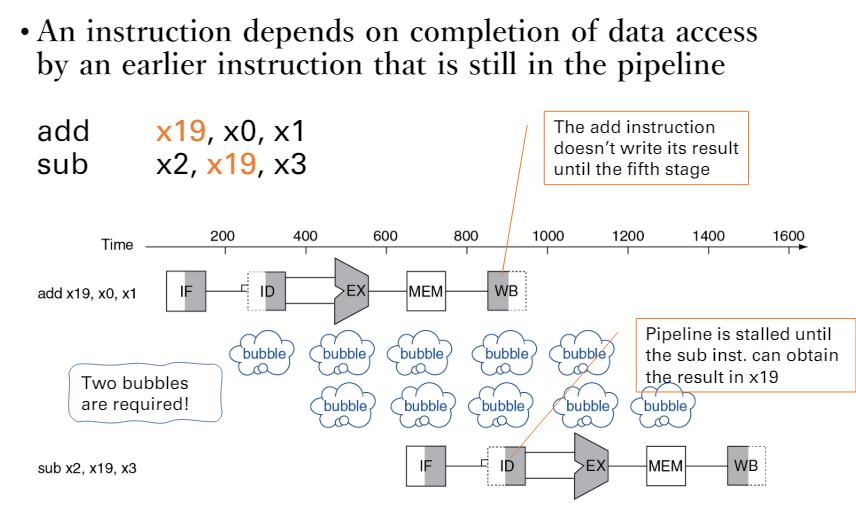
sol.
- forwarding
- 利用硬體的方式 bypassing
- 把結果直接傳給下一個指令
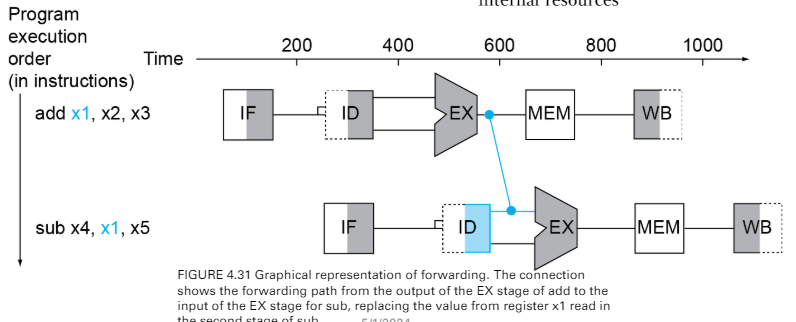
- load-use data hazard
- 需要額外使用bubble
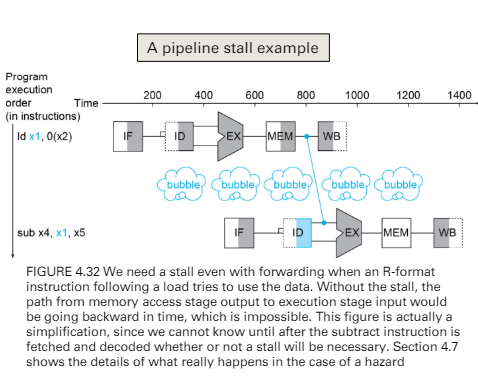
- 需要額外使用bubble
- Code scheduling
- 調整指令執行的順序

- 調整指令執行的順序
Control Hazard
sol.
- stall
- 沒有硬體資源
- 應該需要2次stall

- 應該需要2次stall
- 沒有硬體資源
- prediction
- 用猜的
- static vs. dynamic

- delayed branch
- branch 提早做

- branch 提早做
…
4.7 pipelined datapath and control
…
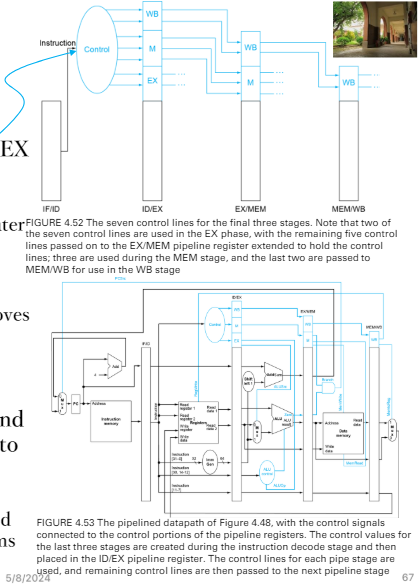
Pipeline control
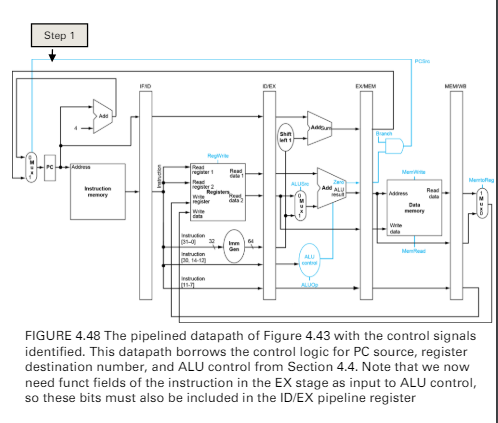
pipeline control on five stage (step 2)
- instruction fetch
- instruction decode/reister file read
- Execution/address calculation
- ALUop and ALUsrc
- memory accedd
- control line set in this stage
- Branch: 資料往後流
- MemRead
- MemWrite
- control line set in this stage
- write-back
- 資料往後流
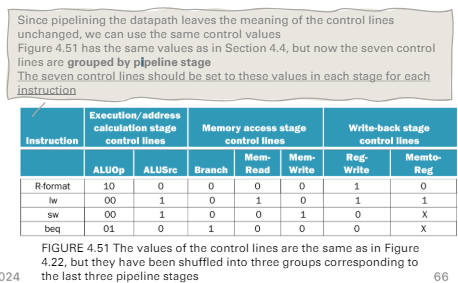
- 比對上一張圖
pipelined control on each stage (step 3)
控制的指令也需要pipeline register
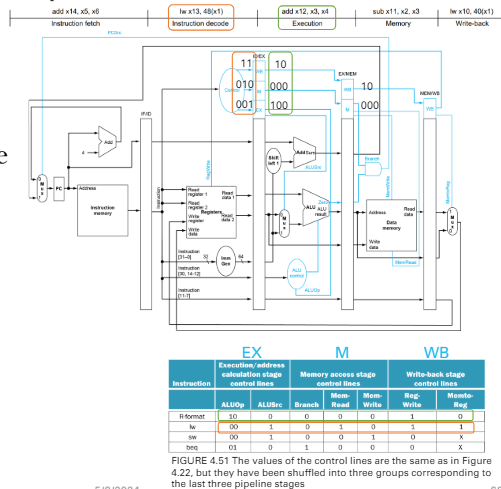
Ex.
4.8 Data Hazards: Forwarding vs. Stalling
Data Hazard in ALU inst.

- 後面四個指令都需要用到sub放進x2的資料
The Dependencies in datapath
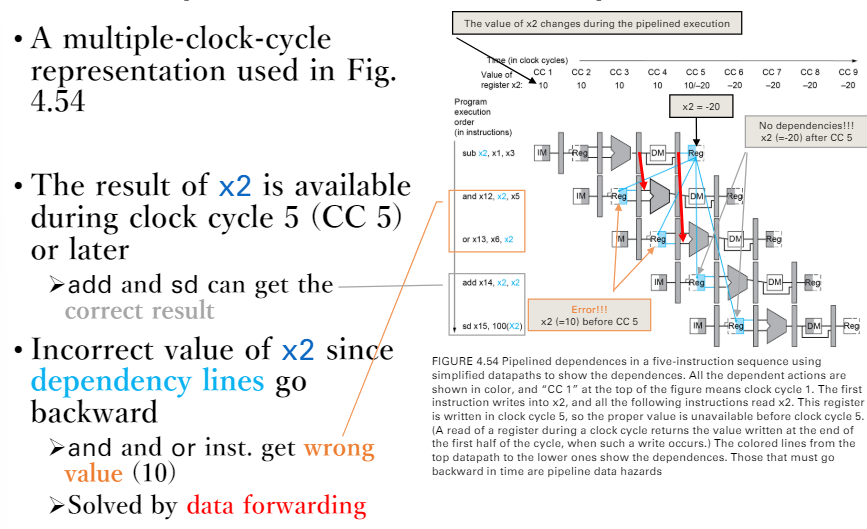
- 正常情況下(CC 5才計算出第一個指令的結果)
- 橘色的部分是不可能做的
- 不能時光回朔 -> 結果是錯的
- 藍色是可以做的
- 紅線是可以forwading的方式(可以解決問題)
- 計算出的結果會被放進pipeline register
- 橘色的部分是不可能做的
Notation
- 如何判斷發生這種情況
- 下一個cycle的rd = 上一個cycle的rs1 or rd2
- 存在dependencies

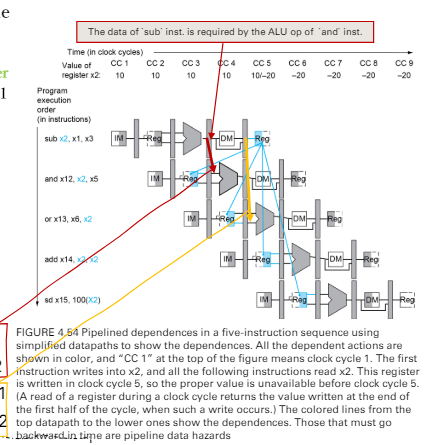
- 也就是比較不同stage的指令
cotrol unit to resolve the hazards
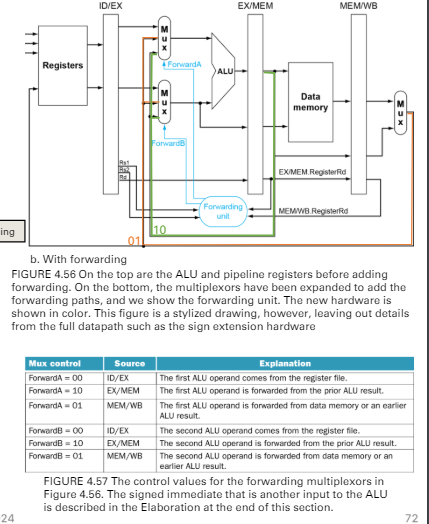
- 綠色是上一張圖的紅色
- forwarding unit

Double data hazard

- 1 and 2, 2 and 3 has dependencies
- 上一種forwarding logic會有問題
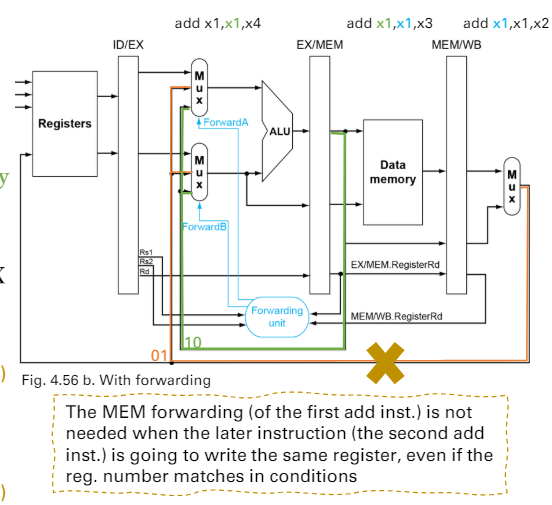
- 兩種forwarding同時match 10 and 01

- 都發生的話
- 確定EX/MEM沒有發生,才讓MEM/WB的forwarding進行(黃字)
data hazard in Load-use inst.
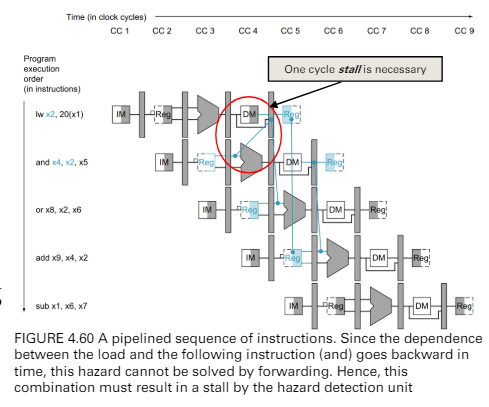
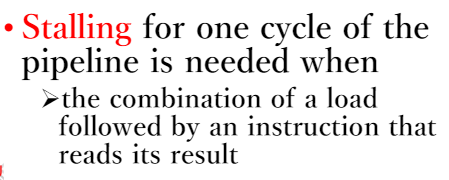
detect
- cc3 發現load的rd = 下一個指令的rs
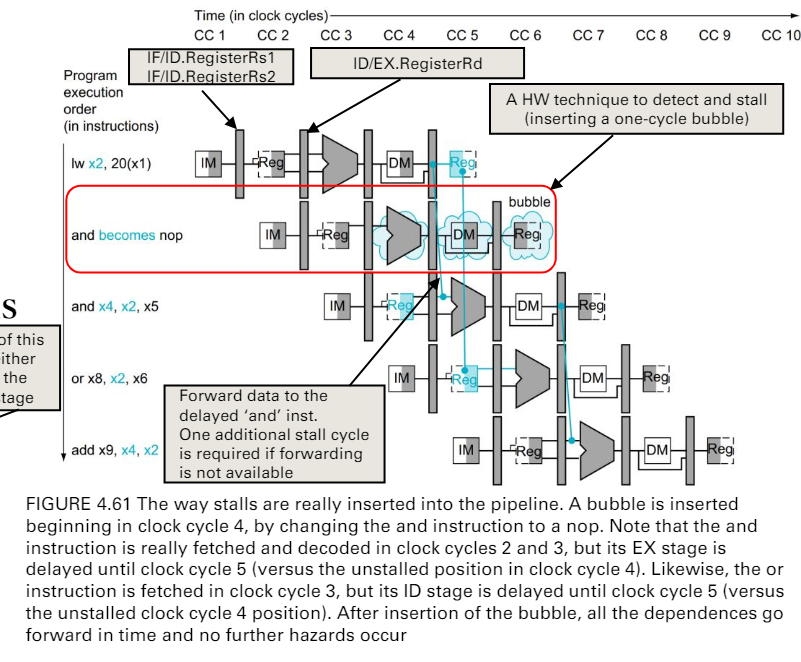
- sw sol. is to insert a NOP
- 如果處理器不能做這件事,compiler就會來做

硬體實作的方法
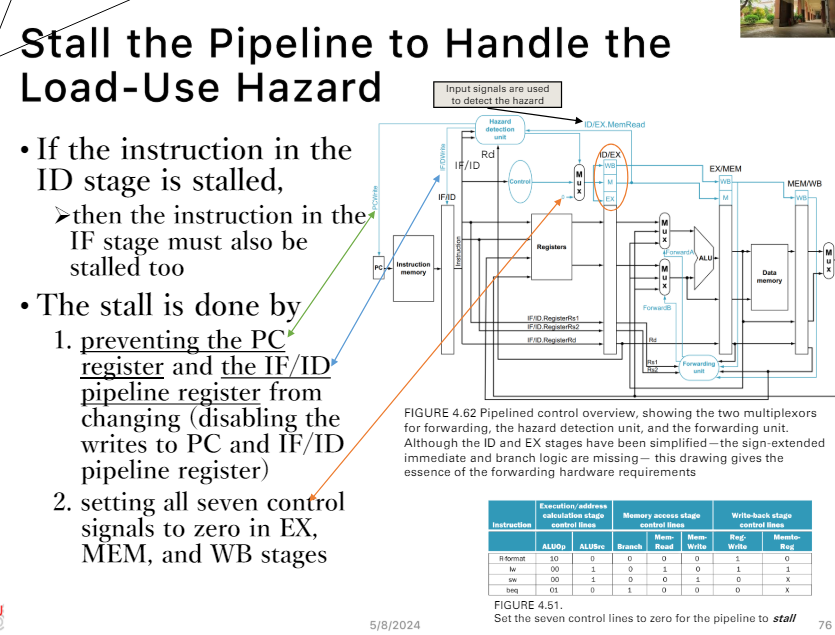
4.9 Control hazards
control hazard
branch 大概會在 MEM stage才知道要不要jump
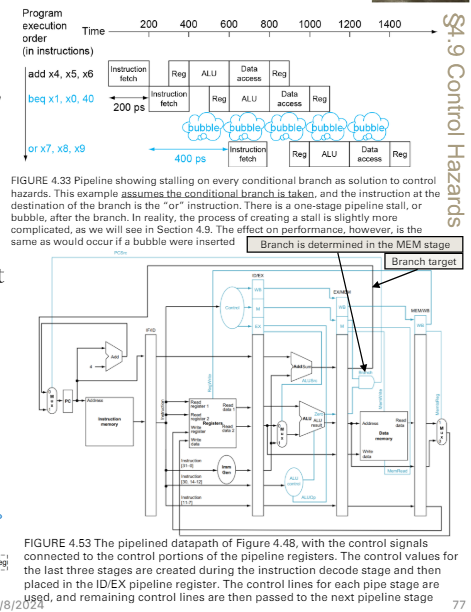
- 基礎設計下,會有3個bubble
- 有其他設計,目的是減少bubble
sol 1. Prediction
prediction覺得不用taken
- 如果正確,繼續執行
- 錯誤,flush掉前面的指令就可以了
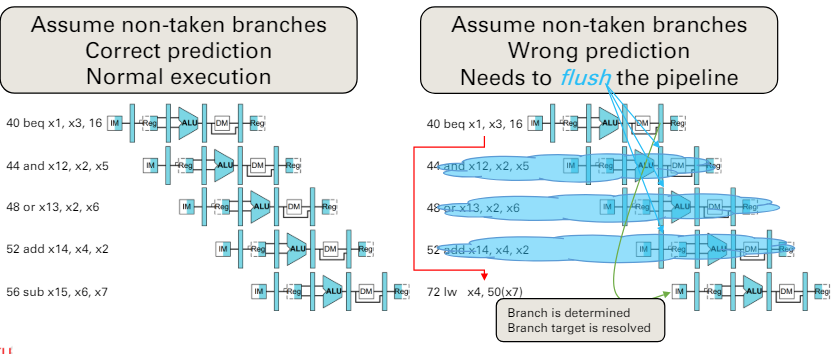
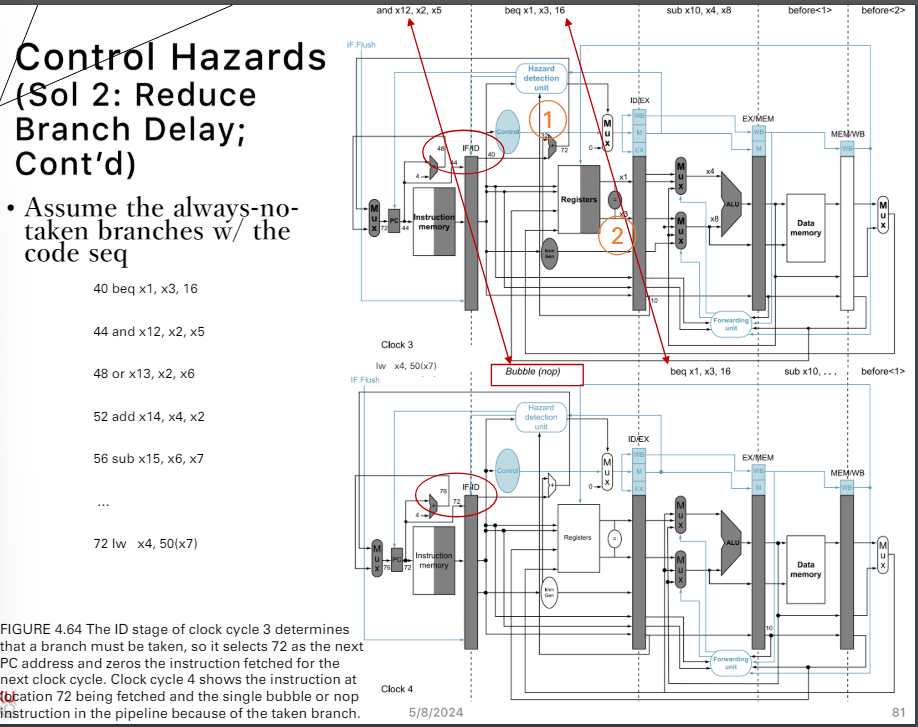
sol 2. Reduce Branch Delay
盡量讓結果更早的算出來
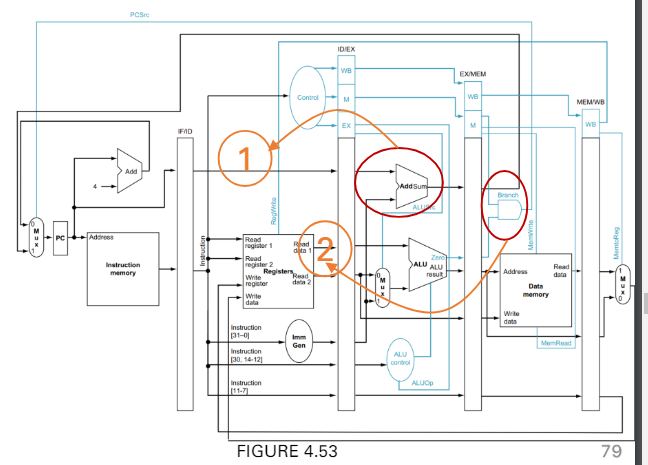
- 1 計算結果可以在ID stage算出來
- 2 可以在ID的後半部就得到
方法

- stall 一個cycle就算得出來
例子
sol 3. Dynamic Branch Prediction
根據程式執行的結果 決定要怎麼做
- 實做一個 branch prediction buffer
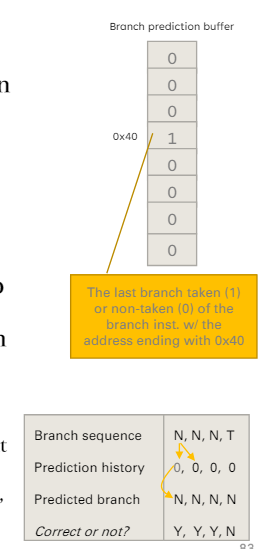
- 計算prediction rate

2-bit branch predictor
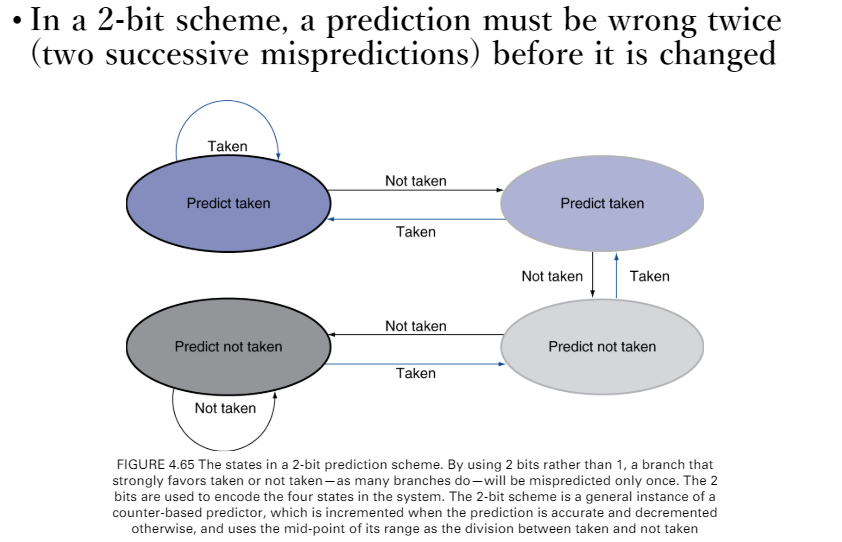
- 錯誤兩次才更換branch prediction buffer
4.10 Exception
Exception
RISC-V的分類

Exception handling
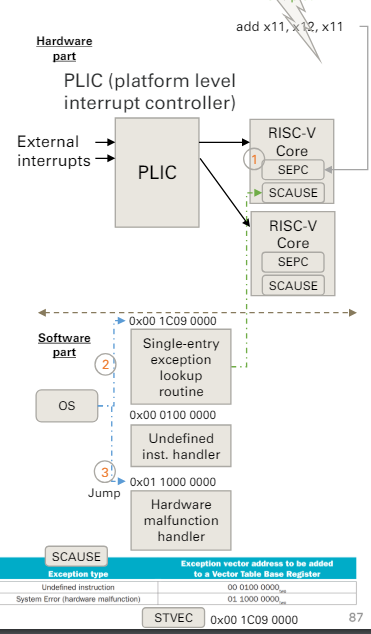
- 發生interrupt就會送到固定的位址
- 類似插入USB等等

- 對應位置會有對應的軟體來處理該狀況
- 做完之後,才會return回去
實作方法
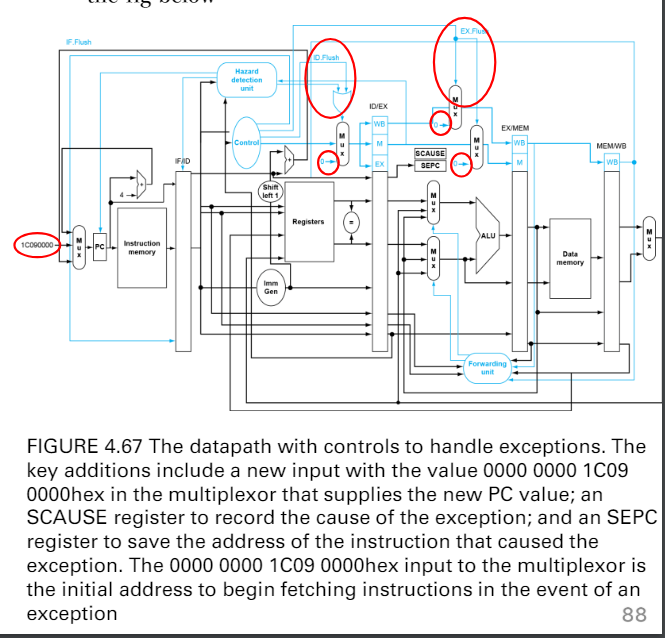

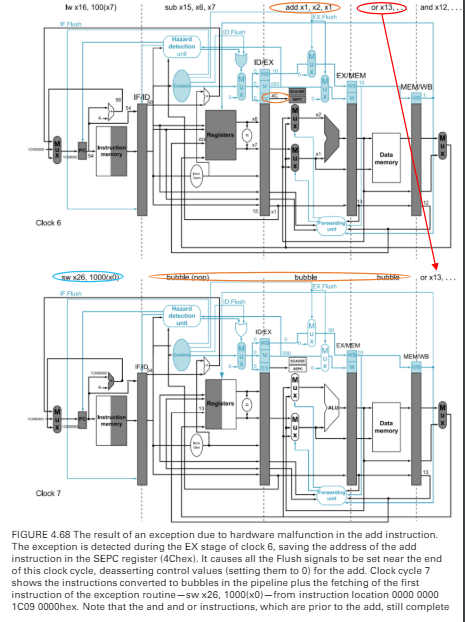
- 把被打斷的指令放進spec

4.11 parallelism via instruction
instruction level parallelism

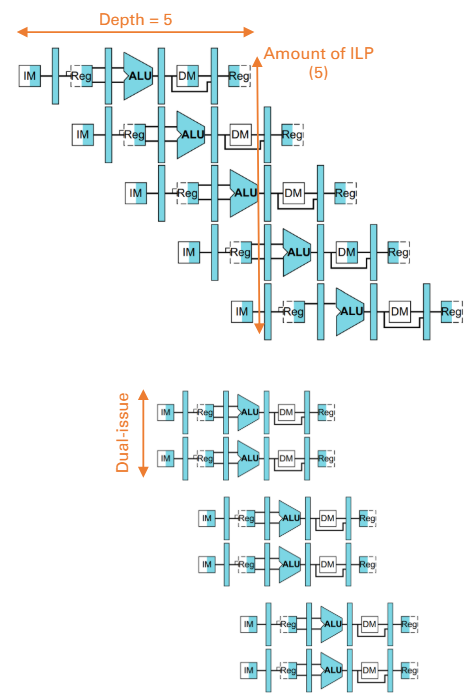
- deeper pipeline
- 管線化的設計是一種Pipeline的展現
- pipeline的深度就是stage數量
- pipeline的深度越多
- ILP平行度越高
- Multiple issue
- 不用CPI來計算效能
Multiple issue processor
- Dynamic
- compiler和處理器決定
- static
- 硬體不做
- compiler做事
Speculation
猜

Static Multiple issue

Ex.

- compiler負責找independent的指令
HW design
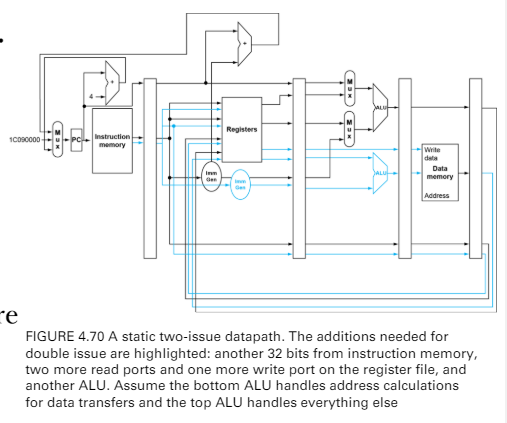

- 現代基本上都是2 issue
Ex.
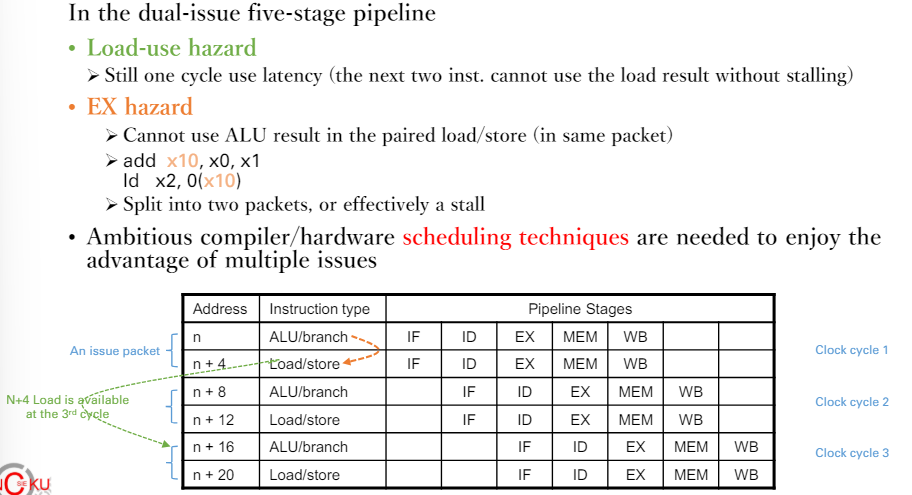
- 一個load 配一個 ALU
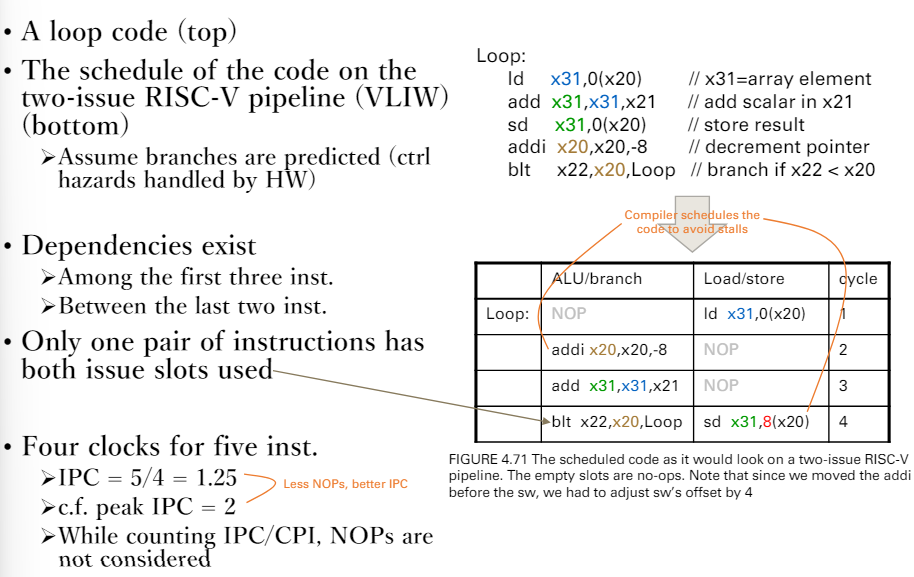
- 用IPC計算
- loop Ex.

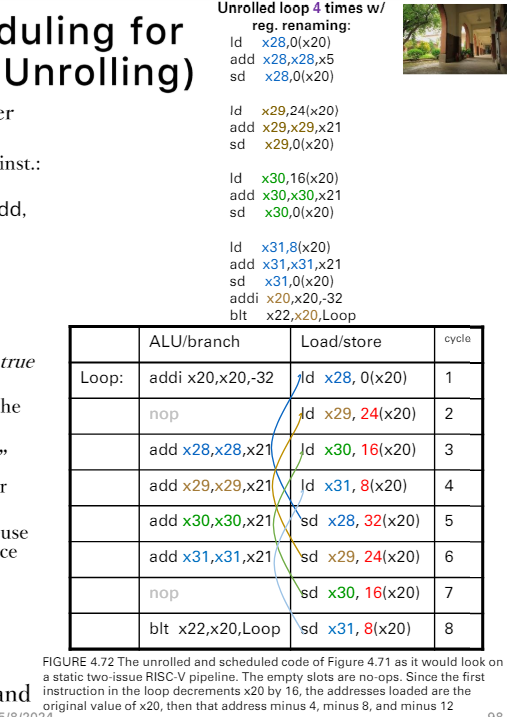
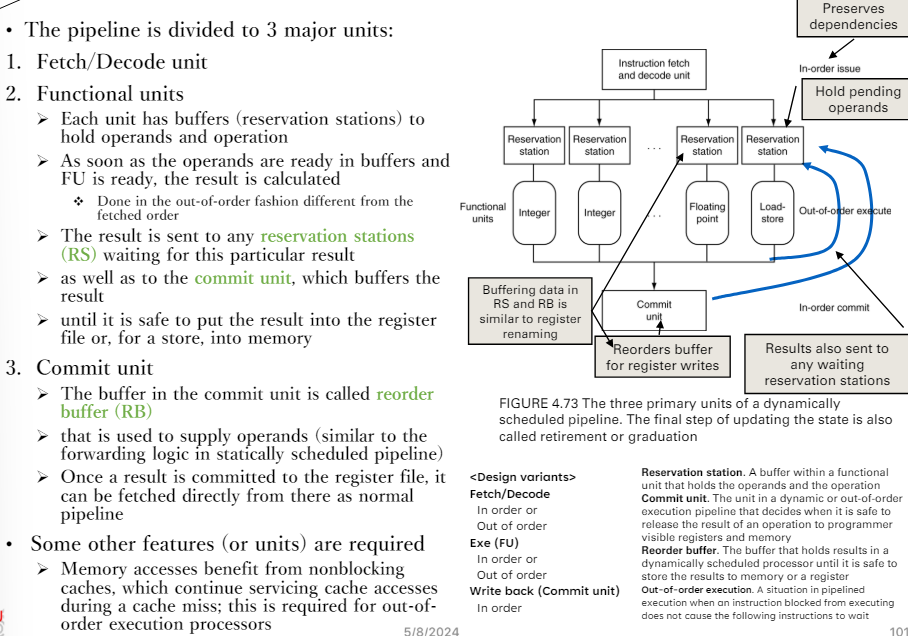
Dynamix Multiple issue
現代手機都是這種
- superscalar

- 部分是in order
Dynamic pipeline scheduling
找沒有相依的指令
- 用一個window去看後面的指令

Ex.
Computer Organization CH4 The Processor
https://z-hwa.github.io/webHome/[object Object]/Computer Organization/Computer-Organization-CH4-The-Processor/